Preemptive Mutitasking
注意事项
在提交的时候,由于换成优先级调度之后make grade不会是满分,所以就把优先级调度所写的算法注释了起来,如果需要检验,可以根据下面优先级调度算法的实现来取消部分注释即可
Part A
所要做的事情:
- 使得JOS支持多CPU处理
- 实现进程调用来允许普通进程创建新的进程
- 实现协作式进程调度
在SMP模型当中CPU分为两类:
- 启动CPU(BSP):负责初始化系统,启动操作系统
- 应用CPU(AP):由BSP启动,具体哪一个CPU是BSP根据硬件以及BISO决定的
在 SMP 系统中,每个 CPU 都有一个附属的 LAPIC 单元。LAPIC 单元用于传递中断,并给它所属的 CPU 一个唯一的 ID。
Exercise 1
首先,我们可以看到在lapic_init()一开始就调用类这个函数,将从lapicaddr开始的4K大小的物理地址映射到了虚拟地址当中,并且返回起始位置,而在mmio_map_region()当中,实际上是调用boot_map_region()来建立所需映射

void *
mmio_map_region(physaddr_t pa, size_t size)
{
// Where to start the next region. Initially, this is the
// beginning of the MMIO region. Because this is static, its
// value will be preserved between calls to mmio_map_region
// (just like nextfree in boot_alloc).
static uintptr_t base = MMIOBASE;
// Reserve size bytes of virtual memory starting at base and
// map physical pages [pa,pa+size) to virtual addresses
// [base,base+size). Since this is device memory and not
// regular DRAM, you'll have to tell the CPU that it isn't
// safe to cache access to this memory. Luckily, the page
// tables provide bits for this purpose; simply create the
// mapping with PTE_PCD|PTE_PWT (cache-disable and
// write-through) in addition to PTE_W. (If you're interested
// in more details on this, see section 10.5 of IA32 volume
// 3A.)
//
// Be sure to round size up to a multiple of PGSIZE and to
// handle if this reservation would overflow MMIOLIM (it's
// okay to simply panic if this happens).
//
// Hint: The staff solution uses boot_map_region.
//
// Your code here:
size = ROUNDUP(size, PGSIZE);
if(size + base > MMIOLIM) //overflow
panic("mmio_map_region overflow MMIOLIM");
int perm = PTE_PCD | PTE_PWT | PTE_W;
boot_map_region(kern_pgdir, base, size, pa, perm);
void *ret = (void *)base;
base += size;
return ret;
}应用处理器(AP)引导程序
在启动AP之前,BSP需要搜集多处理器的信息,比如总共有多少CPU,它们的LAPIC ID以及LAPIC MMIO地址。mp_init()函数从BIOS中读取这些信息。具体代码在mp_init()中,该函数会在进入内核后被i386_init()调用,主要作用就是读取mp configuration table中保存的CPU信息,初始化cpus数组,ncpu(总共多少可用CPU),bootcpu指针(指向BSP对应的CpuInfo结构)。
Exercise 2
Read
boot_aps()andmp_main()inkern/init.c, and the assembly code inkern/mpentry.S. Make sure you understand the control flow transfer during the bootstrap of APs. Then modify your implementation ofpage_init()inkern/pmap.cto avoid adding the page atMPENTRY_PADDRto the free list, so that we can safely copy and run AP bootstrap code at that physical address. Your code should pass the updatedcheck_page_free_list()test (but might fail the updatedcheck_kern_pgdir()test, which we will fix soon).
真正启动AP的是在boot_aps()中,该函数遍历cpus数组,一个接一个启动所有的AP,当一个AP启动后会执行kern/mpentry.S中的代码,然后跳转到mp_main()中,该函数为当前AP设置GDT,TTS,最后设置cpus数组中当前CPU对应的结构的cpu_status为CPU_STARTED。更多关于SMP可以参考
https://pdos.csail.mit.edu/6.828/2018/readings/ia32/MPspec.pdf
对于此程序运行过程的理解:(这时候是运行在启动CPU上,即BSP,工作在保护模式)
i386_init()调用了boot_aps(),开始引导其他的CPU运行

boot_aps()调用memmov(),将代码加载到固定位置

最后调用labpic_startap来执行对应的CPU
而exercise2实际上就是标记MPENTRY_PADDR开始的一个物理页面为已经使用,加一个if判断即可
void
page_init(void)
{
size_t i;
size_t io_hole_start_page = (size_t)IOPHYSMEM / PGSIZE;
size_t kernel_end_page = PADDR(boot_alloc(0)) / PGSIZE; //这里调了半天,boot_alloc返回的是虚拟地址,需要转为物理地址
for (i = 0; i < npages; i++) {
if (i == 0) {
pages[i].pp_ref = 1;
pages[i].pp_link = NULL;
} else if (i >= io_hole_start_page && i < kernel_end_page) {
pages[i].pp_ref = 1;
pages[i].pp_link = NULL;
} else if (i == MPENTRY_PADDR / PGSIZE) {
pages[i].pp_ref = 1;
pages[i].pp_link = NULL;
} else {
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
}
}每个CPU的状态以及初始化
可以通过CpuInfo结构来看到定义的CPU的信息
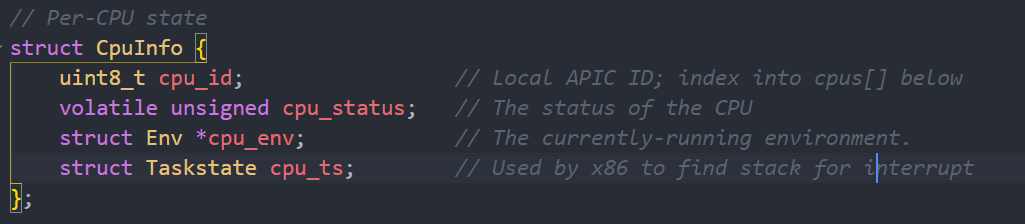
而cpunum()则会返回调用该函数的CPU的ID,而thiscpu的宏定义则是获取当前CPU对应的CpuInfo结构
Exercise 3
Modify
mem_init_mp()(inkern/pmap.c) to map per-CPU stacks starting atKSTACKTOP, as shown ininc/memlayout.h. The size of each stack isKSTKSIZEbytes plusKSTKGAPbytes of unmapped guard pages. Your code should pass the new check incheck_kern_pgdir()
从文档的描述当中我们可以得知,会给每个CPU分配一个内核栈,而BSP(CPU0)的起始位置是KSTACKTOP,每个内核栈的大小回事KSTACKSIZE个字节,而KSTACKGAP字节作为缓冲区检测,防止栈溢出,之后就是CPU1的内核栈,以此类推即可
根据inc/memlayout.h来写对应的映射即可
static void
mem_init_mp(void)
{
// Map per-CPU stacks starting at KSTACKTOP, for up to 'NCPU' CPUs.
//
// For CPU i, use the physical memory that 'percpu_kstacks[i]' refers
// to as its kernel stack. CPU i's kernel stack grows down from virtual
// address kstacktop_i = KSTACKTOP - i * (KSTKSIZE + KSTKGAP), and is
// divided into two pieces, just like the single stack you set up in
// mem_init:
// * [kstacktop_i - KSTKSIZE, kstacktop_i)
// -- backed by physical memory
// * [kstacktop_i - (KSTKSIZE + KSTKGAP), kstacktop_i - KSTKSIZE)
// -- not backed; so if the kernel overflows its stack,
// it will fault rather than overwrite another CPU's stack.
// Known as a "guard page".
// Permissions: kernel RW, user NONE
//
// LAB 4: Your code here:
for (int i = 0; i < NCPU; i++)
{
boot_map_region(kern_pgdir, KSTACKTOP - KSTKSIZE - i * (KSTKSIZE + KSTKGAP),
KSTKSIZE, PADDR(percpu_kstacks[i]), PTE_W);
}
}Exercise 4
每个CPU都需要单独的TSS和TSS描述符来指定对应的内核栈
trap_init_percpu()的作用就是初始化并且加载TSS以及IDT,具体的实现思路就是通过thiscpu来获得当前调用这个函数的CPU的CpuInfo结构,而之后cpuid就更容易了,之后就是thiscpu->cpu_ts当作当前cpu的TSS,而gdt[(GD_TSS0 >> 3) + i]作为TSS描述符
具体实现
void
trap_init_percpu(void)
{
// LAB 4: Your code here:
// Setup a TSS so that we get the right stack
// when we trap to the kernel.
thiscpu->cpu_ts.ts_esp0 = KSTACKTOP - cpuid * (KSTKSIZE + KSTKGAP);
thiscpu->cpu_ts.ts_ss0 = GD_KD;
thiscpu->cpu_ts.ts_iomb = sizeof(struct Taskstate);
// Initialize the TSS slot of the gdt.
gdt[(GD_TSS0 >> 3) + cpunum()] = SEG16(STS_T32A, (uint32_t) (&(thiscpu->cpu_ts)),
sizeof(struct Taskstate) - 1, 0);
gdt[(GD_TSS0 >> 3) + cpunum()].sd_s = 0;
// Load the TSS selector (like other segment selectors, the
// bottom three bits are special; we leave them 0)
ltr(GD_TSS0 + (cpunum() << 3));
// Load the IDT
lidt(&idt_pd);
}锁
多个CPU在同时执行的之后,需要解决可能产生的竞争问题,在这里采用了big kernel lock的全局锁的方法,每个进程可以持有该锁,当进程从用户态向内核态切换的时候加锁,而当退出内核态的时候解锁,这就保证了只有一个CPU能够执行内核态的代码
对应的lock_kernel()和unlock_kernal()定义在spinlock.c当中
Exercise 5
就直接在对应位置加锁解锁就行了
首先在i386_init()函数中,BSP在唤醒其他的CPU的时候加锁
// Starting non-boot CPUs lock_kernel(); boot_aps();在mp_main()当中,AP在执行sched_yield()之前加锁
// Your code here: lock_kernel(); sched_yield();在trap()里面,我们也需要加锁,因为进程从用户态切换到内核态是通过中断来实现的
// LAB 4: Your code here. assert(curenv); lock_kernel();在env_run()当中,当使用完iret实现从内核态退出的啥时候解锁
lcr3(PADDR(e->env_pgdir)); unlock_kernel();//不放到最后是因为在env_pop_tf()后面的语句不会执行到 env_pop_tf(&e->env_tf);
Round—Robin 调度
具体是实现过程
- 实现sched_yield(),该函数的作用是选择一个进程来运行,而之后从当前进程的Env结构开始搜索envs数组,找到下一个可运行的进程,然后调用env_run()在当前cpu来运行新的进程
- 同时实现一个新的系统调用sys_yield(),来进行进程之间的切换
Exercise 6
sched_yield()的功能上面已经提到,按上面说的实现即可,同时还要注意,必须考虑到没有找到合适的进程的情况,此时重新执行前面的进程,否则CPU将会停止运行
void
sched_yield(void)
{
struct Env *idle;
// Implement simple round-robin scheduling.
//
// Search through 'envs' for an ENV_RUNNABLE environment in
// circular fashion starting just after the env this CPU was
// last running. Switch to the first such environment found.
//
// If no envs are runnable, but the environment previously
// running on this CPU is still ENV_RUNNING, it's okay to
// choose that environment.
//
// Never choose an environment that's currently running on
// another CPU (env_status == ENV_RUNNING). If there are
// no runnable environments, simply drop through to the code
// below to halt the cpu.
// LAB 4: Your code here.
int start = 0;
int j;
if (curenv) {
start = ENVX(curenv->env_id) + 1; //从当前Env结构的后一个开始查找
}
for (int i = 0; i < NENV; i++) {
j = (start + i) % NENV;
if (envs[j].env_status == ENV_RUNNABLE) {//找到可以作为下一个运行的进程
env_run(&envs[j]);
}
}
if (curenv && curenv->env_status == ENV_RUNNING) {
env_run(curenv);
}
// sched_halt never returns
sched_halt();
}之后再kern/syscall.c里面加入对应的情况
case SYS_yield:
ret = 0;
sys_yield();
break;在kern/init.c中的用户进程进行修改
#if defined(TEST)
// Don't touch -- used by grading script!
ENV_CREATE(TEST, ENV_TYPE_USER);
#else
// Touch all you want.
ENV_CREATE(user_yield, ENV_TYPE_USER);
ENV_CREATE(user_yield, ENV_TYPE_USER);
ENV_CREATE(user_yield, ENV_TYPE_USER);
#endif // TEST*
// Schedule and run the first user environment!
sched_yield();进程创建的系统调用
现在要实现新的系统调用,该系统调用允许创建进程并且运行新的进程,具体要实现的系统调用如下
- sys_exofork:创建一个新的进程,寄存器与父进程一样,在父进程中返回值为子进程的envid,而在子进程当中返回值为0
- sys_env_set_status:设置一个特定进程的状态为ENV_RUNNABLE或者ENV_NOT_RUNNABLE
- sys_page_alloc:为指定进程分配物理页
- sys_page_map:拷贝页表,使得指定进程能够和当前进程有相同的映射关系
- sys_page_unmap:接触页映射关系
Exercise 7
Implement the system calls described above in
kern/syscall.c. You will need to use various functions inkern/pmap.candkern/env.c, particularlyenvid2env(). For now, whenever you callenvid2env(), pass 1 in thecheckpermparameter. Be sure you check for any invalid system call arguments, returning-E_INVALin that case. Test your JOS kernel withuser/dumbforkand make sure it works before proceeding.
按照上面的来实现对应的系统调用,该联系重点是user/dumbfork.c里面的duppage()函数,它利用 sys_page_alloc() 为子进程分配空闲物理页,再使用sys_page_map() 将该新物理页映射到内核的交换区 UTEMP,方便在内核态进行拷贝操作。在拷贝结束后,利用 sys_page_unmap() 将交换区的映射删除。
sys_exofork()函数
在该函数中,子进程复制了父进程的 trapframe,此后把 trapframe 中的 eax 的值设为了0。最后,返回了子进程的 id。
static envid_t sys_exofork(void) { // Create the new environment with env_alloc(), from kern/env.c. // It should be left as env_alloc created it, except that // status is set to ENV_NOT_RUNNABLE, and the register set is copied // from the current environment -- but tweaked so sys_exofork // will appear to return 0. // LAB 4: Your code here. // panic("sys_exofork not implemented"); struct Env *e; int ret = env_alloc(&e, curenv->env_id); //分配一个Env结构 if (ret < 0) { return ret; } e->env_tf = curenv->env_tf; //寄存器状态保持一致 e->env_status = ENV_NOT_RUNNABLE; //不能运行 e->env_tf.tf_regs.reg_eax = 0; //新进程的返回值为0 return e->env_id; }sys_page_alloc()
在进程envid的地址va分配一个权限为perm的页面
static int sys_page_alloc(envid_t envid, void *va, int perm) { // Hint: This function is a wrapper around page_alloc() and // page_insert() from kern/pmap.c. // Most of the new code you write should be to check the // parameters for correctness. // If page_insert() fails, remember to free the page you // allocated! // LAB 4: Your code here. // panic("sys_page_alloc not implemented"); struct Env *e; int ret = envid2env(envid, &e, 1); //envid对应的env结构 if ((va >= (void*)UTOP) || (ROUNDDOWN(va, PGSIZE) != va)) return -E_INVAL; int flag = PTE_U | PTE_P; if ((perm & flag) != flag) return -E_INVAL; struct PageInfo *pg = page_alloc(1); //分配物理页 if (!pg) return -E_NO_MEM; //未分配成功 ret = page_insert(e->env_pgdir, pg, va, perm); //建立映射关系 if (ret) { page_free(pg); return ret; } return 0; }sys_page_map()函数
static int sys_page_map(envid_t srcenvid, void *srcva, envid_t dstenvid, void *dstva, int perm) { // Hint: This function is a wrapper around page_lookup() and // page_insert() from kern/pmap.c. // Again, most of the new code you write should be to check the // parameters for correctness. // Use the third argument to page_lookup() to // check the current permissions on the page. // LAB 4: Your code here. // panic("sys_page_map not implemented"); struct Env *se, *de; //开始找对应的env结构 int ret = envid2env(srcenvid, &se, 1); if (ret) return ret; ret = envid2env(dstenvid, &de, 1); if (ret) return ret; //之后是相关的条件的判断 if (srcva >= (void*)UTOP || dstva >= (void*)UTOP || ROUNDDOWN(srcva,PGSIZE) != srcva || ROUNDDOWN(dstva,PGSIZE) != dstva) return -E_INVAL; pte_t *pte; struct PageInfo *pg = page_lookup(se->env_pgdir, srcva, &pte); if (!pg) return -E_INVAL; int flag = PTE_U|PTE_P; if ((perm & flag) != flag) return -E_INVAL; if (((*pte&PTE_W) == 0) && (perm&PTE_W)) return -E_INVAL; ret = page_insert(de->env_pgdir, pg, dstva, perm); return ret; }sys_page_ummap()
就是映射关系的清除,可以通过page_remove()来实现
static int sys_page_unmap(envid_t envid, void *va) { // Hint: This function is a wrapper around page_remove(). // LAB 4: Your code here. // panic("sys_page_unmap not implemented"); struct Env *env; int ret = envid2env(envid, &env, 1); if (ret) return ret; if ((va >= (void*)UTOP) || (ROUNDDOWN(va, PGSIZE) != va)) return -E_INVAL; page_remove(env->env_pgdir, va); return 0; }sys_env_set_status()
static int sys_env_set_status(envid_t envid, int status) { // Hint: Use the 'envid2env' function from kern/env.c to translate an // envid to a struct Env. // You should set envid2env's third argument to 1, which will // check whether the current environment has permission to set // envid's status. // LAB 4: Your code here. // panic("sys_env_set_status not implemented"); if (status != ENV_NOT_RUNNABLE && status != ENV_RUNNABLE) return -E_INVAL; struct Env *e; int ret = envid2env(envid, &e, 1); if (ret < 0) return ret; e->env_status = status; return 0; }在
kern/syscall.c里面添加新的系统调用case SYS_exofork: ret = sys_exofork(); break; case SYS_env_set_status: ret = sys_env_set_status((envid_t)a1, (int)a2); break; case SYS_page_alloc: ret = sys_page_alloc((envid_t)a1, (void *)a2, (int)a3); break; case SYS_page_map: ret = sys_page_map((envid_t)a1, (void *)a2,(envid_t)a3, (void *)a4, (int)a5); break; case SYS_page_unmap: ret = sys_page_unmap((envid_t)a1, (void *)a2); break;
Part B
Exercise 8
Exercise 8. Implement the sys_env_set_pgfault_upcall system call. Be sure to enable permission checking when looking up the environment ID of the target environment, since this is a “dangerous” system call.
sys_env_set_pgfault_upcall()
这个系统调用为一个进程设置其用户态的页错误处理函数,当对参数进行检查之后,设置env->env_pgfault_upcall项即可。
static int
sys_env_set_pgfault_upcall(envid_t envid, void *func)
{
// LAB 4: Your code here.
// panic("sys_env_set_pgfault_upcall not implemented");
struct Env *env;
int ret;
if ((ret = envid2env(envid, &env, 1)) < 0) {
return ret;
}
env->env_pgfault_upcall = func;
return 0;
}Exercise 9
Exercise 9. Implement the code in page_fault_handler in kern/trap.c required to dispatch page faults to the user-mode handler. Be sure to take appropriate precautions when writing into the exception stack. (What happens if the user environment runs out of space on the exception stack?)
在这里,我们所需要做的是完善页错误处理函数,我们需要使用户进程遇到也错误trap进入kernel时,kernel能够让用户来运行处理函数
用户程序会用到自己的Exception Stack保存出现中断时的错误信息供处理程序使用,而这个函数就需要将中断时进程的寄存器信息等压入栈中,并运行用户的中断程序。JOS提供了一个结构UTrapframe保存所有要用到的终端信息,只需要在栈中的指定位置分配一块内存给UTrapframe,并将Trapframe的信息存入即可。需要注意用户进程已经在中断栈中运行和第一次触发中断两种情况,对应的esp位置和UTrapframe存放位置也会不同。
void
page_fault_handler(struct Trapframe *tf)
{
uint32_t fault_va;
// Read processor's CR2 register to find the faulting address
fault_va = rcr2();
// Handle kernel-mode page faults.
// LAB 3: Your code here.
if ((tf->tf_cs & 3) == 0)
panic("page_fault_handler():page fault in kernel mode!\n");
// LAB 4: Your code here.
if (curenv->env_pgfault_upcall) {
struct UTrapframe *utf;
uintptr_t New_esp;
//判断是否已经在Exception Stack中
if (tf->tf_esp > UXSTACKTOP - PGSIZE - 1 && tf->tf_esp < UXSTACKTOP)
{
New_esp = tf->tf_esp - sizeof(uint32_t) - sizeof(struct UTrapframe);
utf = (struct UTrapframe*)New_esp;
}
else
{
New_esp = UXSTACKTOP - sizeof(struct UTrapframe);
utf = (struct UTrapframe*)New_esp;
}
//为UTrapframe赋具体值
user_mem_assert(curenv, (void *) New_esp, sizeof(struct UTrapframe), PTE_W | PTE_P | PTE_U);
utf->utf_eflags = tf->tf_eflags;
utf->utf_eip = tf->tf_eip;
utf->utf_err = tf->tf_err;
utf->utf_esp = tf->tf_esp;
utf->utf_fault_va = fault_va;
utf->utf_regs = tf->tf_regs;
curenv->env_tf.tf_esp = New_esp;
curenv->env_tf.tf_eip = (uintptr_t)curenv->env_pgfault_upcall;
env_run(curenv);
}
// Destroy the environment that caused the fault.
cprintf("[%08x] user fault va %08x ip %08x\n",
curenv->env_id, fault_va, tf->tf_eip);
print_trapframe(tf);
env_destroy(curenv);
}Exercise 10
Exercise 10. Implement the _pgfault_upcall routine in lib/pfentry.S. The interesting part is returning to the original point in the user code that caused the page fault. You’ll return directly there, without going back through the kernel. The hard part is simultaneously switching stacks and re-loading the EIP.
要实现的_pgfault_upcall()的作用是调用已经实现的页错误处理程序,并且在运行完处理程序之后返回到原来的进程中继续运行,同时在实现的时候由于返回过程中需要维护寄存器的信息,所以不能直接通过ret,jmp指令实现,而是通过mov来实现
.text
.globl _pgfault_upcall
_pgfault_upcall:
// Call the C page fault handler.
pushl %esp // function argument: pointer to UTF
movl _pgfault_handler, %eax
call *%eax
addl $4, %esp // pop function argument
// LAB 4: Your code here.
// Restore the trap-time registers. After you do this, you
// can no longer modify any general-purpose registers.
// LAB 4: Your code here.
addl $8, %esp // 跳过utf_fault_va和utf_err
movl 40(%esp), %eax // 保存中断发生时的esp到eax
movl 32(%esp), %ecx // 保存终端发生时的eip到ecx
movl %ecx, -4(%eax) // 将中断发生时的esp值亚入到到原来的栈中
popal
addl $4, %esp // 跳过eip
// Restore eflags from the stack. After you do this, you can
// no longer use arithmetic operations or anything else that
// modifies eflags.
// LAB 4: Your code here.
popfl
// Switch back to the adjusted trap-time stack.
// LAB 4: Your code here.
popl %esp
// Return to re-execute the instruction that faulted.
// LAB 4: Your code here.
lea -4(%esp), %esp // 因为之前压入了eip的值但是没有减esp的值,所以现在需要将esp寄存器中的值减4
retExercise 11
Exercise 11. Finish set_pgfault_handler() in lib/pgfault.c.
set_pgfault_handle()为一个进程设置其页错误处理程序。如果程序没有设置处理程序,那么需要调用sys_page_alloc()分配一块Exception Stack,并使用sys_env_set_pgfault_upcall()将中断入口设为完成的汇编程序,最后设置_pagefault_handler()为C语言实现的处理函数即可
void
set_pgfault_handler(void (*handler)(struct UTrapframe *utf))
{
int r;
if (_pgfault_handler == 0) {
// First time through!
// LAB 4: Your code here.
// panic("set_pgfault_handler not implemented");
int r = sys_page_alloc(0, (void *)(UXSTACKTOP-PGSIZE), PTE_W | PTE_U | PTE_P); //分配异常栈
if (r < 0) {
panic("set_pgfault_handler:sys_page_alloc failed");;
}
sys_env_set_pgfault_upcall(0, _pgfault_upcall); //系统调用,设置进程的env_pgfault_upcall属性
}
// Save handler pointer for assembly to call.
_pgfault_handler = handler;
}Exercise 12
Exercise 12. Implement fork, duppage and pgfault in lib/fork.c.
Test your code with the forktree program. It should produce the following messages, with interspersed ‘new env’, ‘free env’, and ‘exiting gracefully’ messages. The messages may not appear in this order, and the environment IDs may be different.
pgfault()
该函数实现的是Copy On Write式的fork()函数遇到也错误时候的处理程序,由于COW式的fork()创建出来的子进程一开始就和父进程共享物理内存,因此,当父进程或者子进程要修改一个物理内存页的时候,需要新的一页物理内存来避免冲突
判断一下参数合法与否,在这里与之前稍有不同的是还需要判断当前要处理的页是否是一个COW页,以及是否由于写操作引起的页错误。判断方式与之前相同(使用JOS定义好的
FEC_WR测试err,使用PTE_COW检查页表项标志位)。随后首先用
sys_page_alloc()为进程希望修改的COW页分配新的物理内存,再取消引发页错误的虚拟地址原有的映射,并将刚才映射在缓存区的新页映射给addr,最后取消缓存区的映射即可。中间每一步都需要检查是否有错误产生。
static void
pgfault(struct UTrapframe *utf)
{
void *addr = (void *) utf->utf_fault_va;
uint32_t err = utf->utf_err;
int r;
// LAB 4: Your code here.
uint32_t pgnum = PGNUM(addr);
uint32_t pgde = PDX(addr);
envid_t envid = sys_getenvid();
if (!((err&FEC_WR) && (uvpt[pgnum]&PTE_COW) && (uvpt[pgnum]&PTE_P) && (uvpd[pgde]&PTE_P)))
panic("Page cannot be fixed\n");
addr = ROUNDDOWN(addr,PGSIZE);
if (sys_page_alloc(envid,(void*)PFTEMP,PTE_W|PTE_P|PTE_U) < 0)
panic("sys_page_alloc panic\n");
memmove(PFTEMP,addr,PGSIZE);
if (sys_page_unmap(envid,addr) < 0)
panic("sys_page_unmap panic\n");
if (sys_page_map(envid, PFTEMP, envid, addr, PTE_P|PTE_U|PTE_W) < 0)
panic("sys_page_map panic\n");
if (sys_page_unmap(envid,PFTEMP) < 0)
panic("sys_page_unmap panic\n");
}- deppage()
该函数的作用式将虚拟内存也好为pn的虚拟内存映射到一个给定进程的相同虚拟空间,实现上只需要调用sys_page_map()即可
static int
duppage(envid_t envid, unsigned pn)
{
int r;
// LAB 4: Your code here.
void *addr = (void *)(pn*PGSIZE);
envid_t thisenvid = sys_getenvid();
if ((uvpt[pn]&PTE_W) || (uvpt[pn]&PTE_COW))
{
if (sys_page_map(thisenvid, addr, envid, addr, PTE_P|PTE_U|PTE_COW) < 0)
panic("sys_page_map dupage");
if (sys_page_map(thisenvid, addr, thisenvid, addr, PTE_P|PTE_U|PTE_COW) < 0)
panic("sys_page_map dupage");
} else
{
if (sys_page_map(thisenvid, addr, envid, addr, PTE_P|PTE_U) < 0)
panic("sys_page_map dupage");
}
return 0;
}- fork()
一个进程调用这个fork()后,首先会将进程的页错误处理函数设置为刚才实现的COW专用页错误处理函数;随后调用sys_exofork()产生一个新的进程。但是这里产生的新进程仅仅是复制了父进程的寄存器信息,接下来需要完成子进程的内存映射。在父进程中,首先需要将UTEXT到Exception Stack之间的用户内存映射给子进程。这里要用到刚才实现的duppage()函数来进行逐页映射(需要处理COW)。随后要给这个进程分配自己的Exception Stack,并初始化其中断处理函数,最后将子进程状态设为ENV_RUNNABLE,返回子进程id。子进程中fork()返回0即可
envid_t
fork(void)
{
// LAB 4: Your code here.
uint32_t err;
set_pgfault_handler(pgfault); // 缺页处理函数
envid_t envid = sys_exofork();// 产生新的进程,设置了进程的状态,复制寄存器(TrapFrame)
if (envid == -E_NO_FREE_ENV ||envid == -E_NO_MEM){
panic("cannot allocate an environment for %e\n", envid);
}
if (envid > 0){
// 父进程
for (uint32_t pn = PGNUM(UTEXT); pn < PGNUM(UXSTACKTOP - PGSIZE); pn++){
if (((uvpd[PDX(pn*PGSIZE)]&PTE_P) != PTE_P) || ((uvpt[pn]&PTE_P) != PTE_P)) continue;
if ((err = duppage(envid, pn)) < 0)
panic("duppage err:%e\n", err);
}
if ((err = sys_page_alloc(envid, (void *)(UXSTACKTOP - PGSIZE), PTE_P|PTE_U|PTE_W)) < 0)
panic("sys_page_alloc err:%e\n", err);
extern void _pgfault_upcall();
if ((err =sys_env_set_pgfault_upcall(envid, _pgfault_upcall))< 0)
panic("sys_env_set_pgfault_upcall err:%e\n", err);
if ((err = sys_env_set_status(envid, ENV_RUNNABLE)) < 0)
panic("sys_env_set_status err:%e\n", err);
}
else{
//子进程
thisenv = &envs[ENVX(sys_getenvid())];
return 0;
}
return envid;
}Part C
Exercise 13
Exercise 13. Modify kern/trapentry.S and kern/trap.c to initialize the appropriate entries in the IDT and provide handlers for IRQs 0 through 15. Then modify the code in env_alloc() in kern/env.c to ensure that user environments are always run with interrupts enabled.
trapentry.s
TRAPHANDLER_NOEC(handler32, IRQ_OFFSET + IRQ_TIMER)
TRAPHANDLER_NOEC(handler33, IRQ_OFFSET + IRQ_KBD)
TRAPHANDLER_NOEC(handler34, 34)
TRAPHANDLER_NOEC(handler35, 35)
TRAPHANDLER_NOEC(handler36, IRQ_OFFSET + IRQ_SERIAL)
TRAPHANDLER_NOEC(handler37, 37)
TRAPHANDLER_NOEC(handler38, 38)
TRAPHANDLER_NOEC(handler39, IRQ_OFFSET + IRQ_SPURIOUS)
TRAPHANDLER_NOEC(handler40, 40)
TRAPHANDLER_NOEC(handler41, 41)
TRAPHANDLER_NOEC(handler42, 42)
TRAPHANDLER_NOEC(handler43, 43)
TRAPHANDLER_NOEC(handler44, 44)
TRAPHANDLER_NOEC(handler45, 45)
TRAPHANDLER_NOEC(handler46, IRQ_OFFSET + IRQ_IDE)
TRAPHANDLER_NOEC(handler47, 47)
TRAPHANDLER_NOEC(handler51, IRQ_OFFSET + IRQ_ERROR)trap_init()
void handler32();
void handler33();
void handler34();
void handler35();
void handler36();
void handler37();
void handler38();
void handler39();
void handler40();
void handler41();
void handler42();
void handler43();
void handler44();
void handler45();
void handler46();
void handler47();
void handler51();
...
SETGATE(idt[IRQ_OFFSET + 0], 0, GD_KT, handler32, 0);
SETGATE(idt[IRQ_OFFSET + 1], 0, GD_KT, handler33, 0);
SETGATE(idt[IRQ_OFFSET + 2], 0, GD_KT, handler34, 0);
SETGATE(idt[IRQ_OFFSET + 3], 0, GD_KT, handler35, 0);
SETGATE(idt[IRQ_OFFSET + 4], 0, GD_KT, handler36, 0);
SETGATE(idt[IRQ_OFFSET + 5], 0, GD_KT, handler37, 0);
SETGATE(idt[IRQ_OFFSET + 6], 0, GD_KT, handler38, 0);
SETGATE(idt[IRQ_OFFSET + 7], 0, GD_KT, handler39, 0);
SETGATE(idt[IRQ_OFFSET + 8], 0, GD_KT, handler40, 0);
SETGATE(idt[IRQ_OFFSET + 9], 0, GD_KT, handler41, 0);
SETGATE(idt[IRQ_OFFSET + 10], 0, GD_KT, handler42, 0);
SETGATE(idt[IRQ_OFFSET + 11], 0, GD_KT, handler43, 0);
SETGATE(idt[IRQ_OFFSET + 12], 0, GD_KT, handler44, 0);
SETGATE(idt[IRQ_OFFSET + 13], 0, GD_KT, handler45, 0);
SETGATE(idt[IRQ_OFFSET + 14], 0, GD_KT, handler46, 0);
SETGATE(idt[IRQ_OFFSET + 15], 0, GD_KT, handler47, 0);
SETGATE(idt[IRQ_OFFSET + 19], 0, GD_KT, handler51, 0);env_alloc()
// Enable interrupts while in user mode.
// LAB 4: Your code here.
e->env_tf.tf_eflags |= FL_IF;Exercise 14
Exercise 14. Modify the kernel’s trap_dispatch() function so that it calls sched_yield() to find and run a different environment whenever a clock interrupt takes place.
trap_dispatch()
修改trap_dispatch(),使得时钟中断发生时,切换到另一个进程执行,按照提示来就可以
static void
trap_dispatch(struct Trapframe *tf)
{
...
// Handle clock interrupts. Don't forget to acknowledge the
// interrupt using lapic_eoi() before calling the scheduler!
// LAB 4: Your code here.
if (tf->tf_trapno == IRQ_OFFSET + IRQ_TIMER) {
lapic_eoi();
sched_yield();
// return;
}
...
}Exercise 15
Exercise 15. Implement sys_ipc_recv and sys_ipc_try_send in kern/syscall.c. Read the comments on both before implementing them, since they have to work together. When you call envid2env in these routines, you should set the checkperm flag to 0, meaning that any environment is allowed to send IPC messages to any other environment, and the kernel does no special permission checking other than verifying that the target envid is valid.
Then implement the ipc_recv and ipc_send functions in lib/ipc.c.
sys_ipc_recv()和sys_ipc_try_send()是怎么协作的:
当某个进程调用
sys_ipc_recv()后,该进程会阻塞(状态被置为ENV_NOT_RUNNABLE),直到另一个进程向它发送“消息”。当进程调用sys_ipc_recv()传入dstva参数时,表明当前进程准备接收页映射。进程可以调用
sys_ipc_try_send()向指定的进程发送“消息”,如果目标进程已经调用了sys_ipc_recv(),那么就发送数据,然后返回0,否则返回-E_IPC_NOT_RECV,表示目标进程不希望接受数据。当传入srcva参数时,表明发送进程希望和接收进程共享srcva对应的物理页。如果发送成功了发送进程的srcva和接收进程的dstva将指向相同的物理页。
sys_ipc_recv()
需要实现的是进程接受ipc的函数。按惯例检查传入参数,然后分别设置进程自己的ipc接收状态和接收地址,将自己阻塞(状态设为ENV_NOT_RUNNABLE)最后调用sched_yield()运行其他程序即可
static int
sys_ipc_recv(void *dstva)
{
// LAB 4: Your code here.
if(dstva < (void*)UTOP && PGOFF(dstva) != 0)
return -E_INVAL;
curenv->env_ipc_recving = true;
curenv->env_ipc_dstva = dstva;
curenv->env_ipc_from = 0;
curenv->env_status = ENV_NOT_RUNNABLE;
sched_yield();
return 0;
}sys_ipc_try_send()
实现了IPC的发送端函数,将一个值value和一个虚拟地址为srcva的内存页发送给指定的进程。在检查参数后,调用page_lookup()函数查找srcva对应的内存页,并用page_insert()将这个物理页映射给接收进程的指定地址dstva。通过直接设置目标进程的env_ipc_value值即可完成值的传递,并需要以同样方式告知对方发送程序的envid。
static int
sys_ipc_try_send(envid_t envid, uint32_t value, void *srcva, unsigned perm)
{
// LAB 4: Your code here.
struct Env * envstore;
if (envid2env(envid, &envstore, 0) != 0)
return -E_BAD_ENV;
if (envstore->env_ipc_recving == 0)
return -E_IPC_NOT_RECV;
if (srcva < (void *)UTOP) {
if ((uintptr_t)srcva % PGSIZE != 0)
return -E_INVAL;
if (((perm&(~(PTE_U|PTE_P|PTE_AVAIL|PTE_W))) != 0)||((perm&(PTE_U | PTE_P)) != (PTE_U | PTE_P)))
return -E_INVAL;
pte_t* pte;
struct PageInfo *pg = page_lookup(curenv->env_pgdir, srcva, &pte);
if (pg == NULL)
return -E_INVAL;
if ((perm & PTE_W) && !(*pte & PTE_W))
return -E_INVAL;
if ((uintptr_t)(envstore->env_ipc_dstva) < UTOP) {
uint32_t ret;
if ((ret = page_insert(envstore->env_pgdir, pg, envstore->env_ipc_dstva, perm)) != 0)
return ret;
envstore->env_ipc_perm = perm;
}
else envstore->env_ipc_perm = 0;
}
envstore->env_ipc_recving = 0;
envstore->env_ipc_from = curenv->env_id;
envstore->env_ipc_value = value;
envstore->env_status = ENV_RUNNABLE;
envstore->env_tf.tf_regs.reg_eax = 0;
return 0;
}ipc_recv()
用户库函数中的ipc接收端。它的主要功能是在接收完成后,判断是否收到了信息,收到了则存入from_env_store和perm_store中,并返回ipc接受到的value。
int32_t
ipc_recv(envid_t *from_env_store, void *pg, int *perm_store)
{
// LAB 4: Your code here.
if (pg == NULL)
pg = (void *)KERNBASE;
uint32_t ret = sys_ipc_recv(pg);
if (ret != 0) {
if (from_env_store) *from_env_store = 0;
if (perm_store) *perm_store = 0;
return ret;
}
if (from_env_store) *from_env_store =thisenv->env_ipc_from;
if (perm_store) *perm_store = thisenv->env_ipc_value;
return thisenv->env_ipc_value;
}ipc_send()
void
ipc_send(envid_t to_env, uint32_t val, void *pg, int perm)
{
// LAB 4: Your code here.
uint32_t ret = 1;
if (pg == NULL)
pg = (void *)KERNBASE;
while (ret != 0) {
ret = sys_ipc_try_send(to_env, val, pg, perm);
if (ret < 0 && ret != -E_IPC_NOT_RECV)
panic("ipc_send:%e", ret);
sys_yield();
}
}运行结果
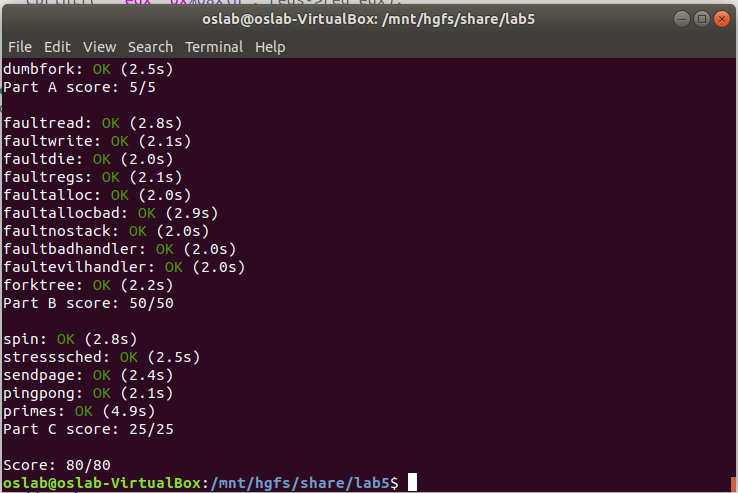
优先级调度
优先级调度函数
我们要实现一个优先级调度函数sched_priority_yield(),作用是根据进程的优先级来选择所要运行的进程,而不是像之前一样,运行找到的第一个可运行进程
实现思路:此时的优先级应该是在Env结构中存储的,要修改env结构,在里面加入一项int env_priority来存储当前进程的优先级,并且在env_alloc()时初始化为-1,而之后的话就只是按照时间顺序来逐渐升高优先级
而我们的调度函数所要做的就是遍历所有的进程,找到可运行并且优先级最高的那个并且运行它
具体实现
//choose a user environment that is both runnable and have the most priority
void
sched_yield(void)
{
struct Env *idle;
uint32_t env_index;
uint32_t first_env_index;
static uint32_t prior = 0;
idle = thiscpu->cpu_env;
if(idle == NULL)
first_env_index = env_index = -1;
else{
first_env_index = env_index = ENVX(idle->env_id);
if(idle->env_priority == -1) //等待时间越长,优先级越高
idle->env_priority = prior++;
}
for(uint32_t i = 0; i < NENV; i++)
{
uint32_t n = (env_index + i) % NENV;
//给没有被调度过的进程设置优先级
if(envs[n].env_status == ENV_RUNNABLE && envs[n].env_priority == -1)
envs[n].env_priority = prior++;
//找到优先级最高的进程
if(envs[n].env_status == ENV_RUNNABLE && envs[n].env_priority > envs[first_env_index].env_priority)
first_env_index = n;
}
if(first_env_index != -1){
env_run(&envs[first_env_index]);
return;
}
if(idle && idle->env_status == ENV_RUNNING){
env_run(idle);
return;
}
sched_halt();
}之后我们需要参考user/yield.c来实现我们的测试文件,我是在原来的基础上直接修改的
#include <inc/lib.h>
void
umain(int argc, char **argv)
{
int i;
cprintf("Hello, I am environment %08x. Priority: %d\n", thisenv->env_id, thisenv->env_priority);
for (i = 0; i < 3; i++) {
sys_yield();
cprintf("Back in environment %08x, iteration %d.\n", thisenv->env_id, i);
}
cprintf("All done in environment %08x.\n", thisenv->env_id);
}运行结果
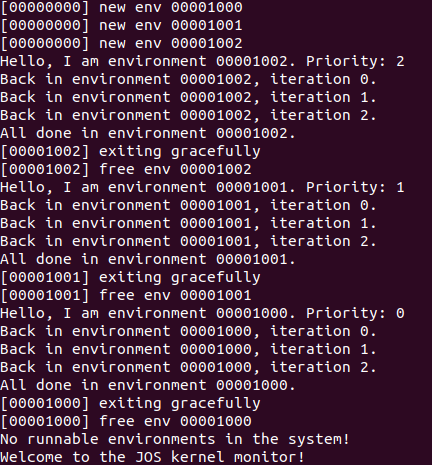
问题回答
在kern/init.c当中,BSP通过运行i386_init()来完成内存、进程等的初始化,之后就开始了APs的初始化过程,通过调用mp_init()以及lapic_init()两个函数来完成基本的信息收集以及APIC初始化
mp_init()首先从BIOS中获取多处理器配置信息。在BIOS所在的内存区中可以读取MP配置表获得CPU总数,APIC ID,LAPIC的内存映射地址等。随后则由lapic_init()初始化LAPIC上的寄存器。
在得到基本的CPU信息之后,会转到boot_aps(),由它来一个一个的启动找到的APs。
在mpentry中,AP从实模式启动,这里与boot.S类似。这时会进行寄存器初始化,GDT载入,设置页表和分页,初始化堆栈等工作。完成后mpentry会调用mp_main()继续进行AP启动工作,设置页表目录,建立LAPIC的MMIO映射,初始化GDT与TSS,设置CPU状态。
回到boot_aps(),只有当程序确认一个AP启动完成(CPU状态为CPU_STARTED)后,才会继续启动下一个AP;否则会一直忙等。
当一个用户程序调用COW fork(即lib中的
fork())时,fork()首先会将用户程序的页错误处理程序设置为COW专用的pgfault()函数随后会调用
sys_exofork()来实现基本的fork进程创建。
在这些步骤中,第一步会涉及到sys_page_alloc()(分配异常处理栈)和sys_env_set_pgfault_upcall()(设置页错误处理程序)。而在用duppage()复制COW页过程中,则会调用sys_getenvid()和sys_page_map()两个系统调用。最后还会用到sys_env_set_status()设定进程状态。
在用户程序发生一个页错误后,系统都会陷入内核,调用一般的内核中断处理程序。当中断处理被分发给trap.c中的
page_fault_handler()中后,内核的页错误处理程序则会将UTrapframe压入Exception Stack,并开始运行进程自己的COW页错误处理程序pgfault()。之后系统又一次回到用户态,并且执行完成后直接回到用户进程。而在
pgfault()中,处理函数会判断页错误类型是否是写入一个COW页面造成的,如果是则将要写入的COW页复制一个,并分配给当前进程的内存空间。
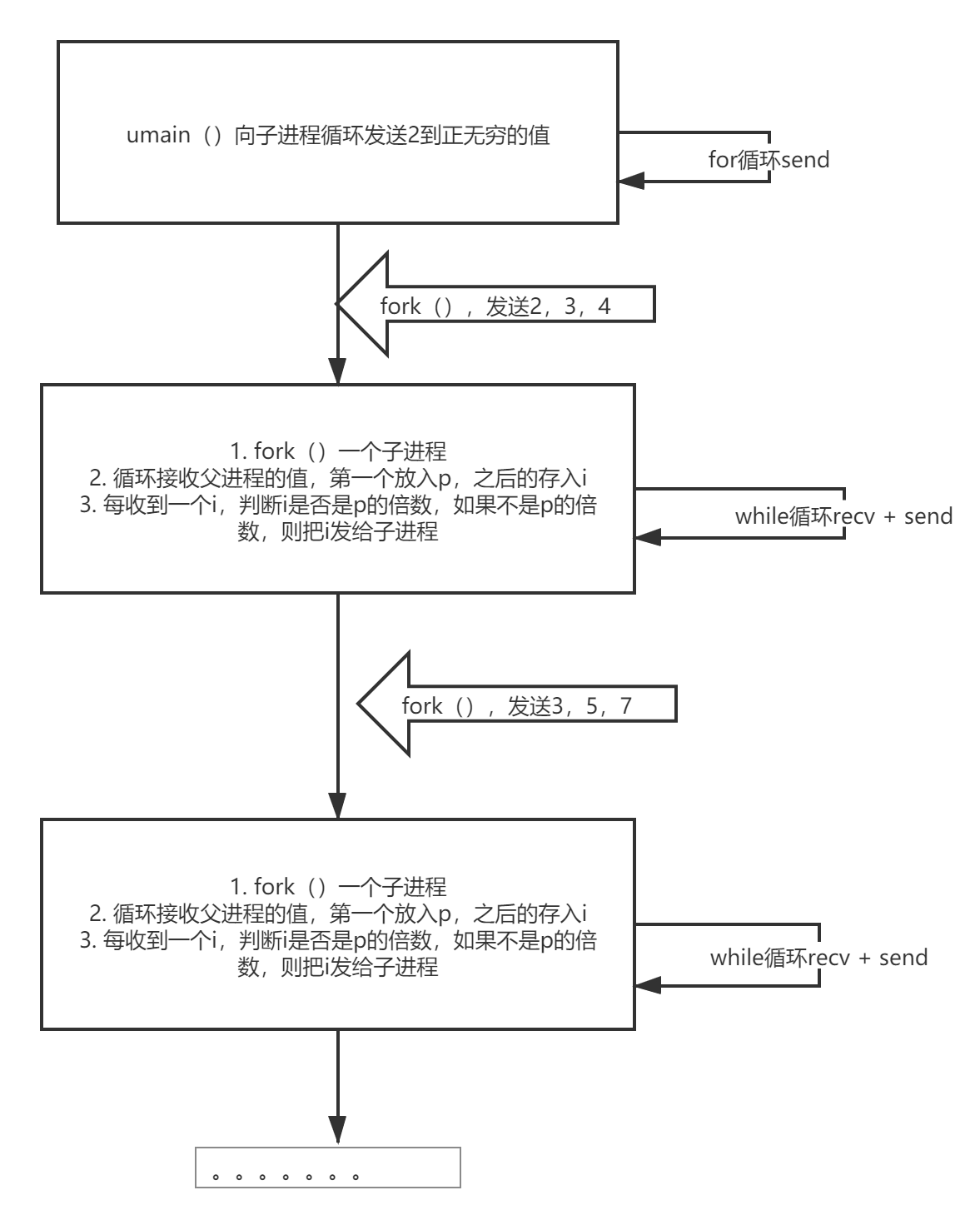
这段代码实际上就是由一个进程创建一个子进程后,不断地给子进程发送一些数字。每个被创建出来的子进程同样会再创建出一个孩子进程,然后不断给子进程发送数字。main进程发送从2开始的自然数给子进程,子进程留下第一个数字2,即为这个子进程找到的素数。而后子进程会将所有2的倍数筛掉,将剩下的数字再发给自己的子进程(这里也就是main进程子进程的子进程),由被fork出的进程重复这个过程。而每个进程留下的第一个数字一定是素数,因为这个数已经被比他小的数字检验过了–如果是比他小的数字的倍数,会被筛选掉。而这样每个进程就都能够找到一个素数。
代码流程图:
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!