设计文档
姓名:贾昊龙
学号:18307130049
同组人员:唐宸
文档说明
| 文件 | 作用说明 |
|---|---|
| 1.png | 根据高频词制作的词云 |
| cn_stopwords.txt | Github上面获取的常用中文停用词 |
| movie4.csv | 将另一位同学所爬数据整合后的源数据文件 |
| PJ.py | 主文件,具体实现 |
| word_csv.csv | 按照出现次数排序后制作出的词频统计 |
负责部分
在这一个part,我负责来实现对于另外一名同学通过爬虫爬取的数据的分词、词频统计以及制作词云的工作,此外,我还实现了2018-2020不同月份弹幕数量的对比(通过并列柱状图来显示)
具体实现
分词
首先,我们可以看到在原始的数据文件movie.csv当中(我将另一位同学爬取的三分数据放到了一个csv文件当中),这些原始数据还带有时间表示,在通过调用jieba.lcut()进行中文分词之后,对于一些我认为并不能反映实际意思的词语,我进行了删去,除此之外,对于一些常见的停用词,我从GitHub上面获取到了一个text文件,通过导入text文件来作为停用词的一个词典
具体实现:
file = open("movie4.csv", 'r', encoding="utf-8")
text = file.read()
file.close()
print("读取成功,开始进行分词并制作词云")
word_txt = jieba.lcut(text) #进行中文分词
stops_word = open("cn_stopwords.txt", 'r', encoding="utf-8").read() #导入常见停用词词典
exclude = {"马老师", "英国大力士", "婷婷", "不讲武德", "耗子尾汁", "哈哈哈哈", "没", "说","真","2020","08","01","02","03","04","05","06","07","08","09","10","11","12","13","14","15","哈哈哈"
"25","26","17","30","16","18","31","22","2018","2019",
"20","21","29","19","28","27","23","24"} #自定义当前的停用词
stop_list = stops_word.split()
stops_all = set(stop_list).union(set(stop_list), exclude) #二者的并集
word_list = [element for element in word_txt if element not in stops_all] #去除停用词之后的word list此时我们已经对于实现了一部分分词,同时,针对于这部电影而言,可能有一些“专有名词”出现,例如:张麻子,让子弹飞等等,为了词频以及词云的准确性,我进行了添加
jieba.add_word("张麻子") #添加特殊的分词
jieba.add_word("师爷")
jieba.add_word("麻子")
jieba.add_word("讲真的")
jieba.add_word("让子弹飞")
jieba.add_word("名场面")此时我们其实已经完成了分词部分
词频统计
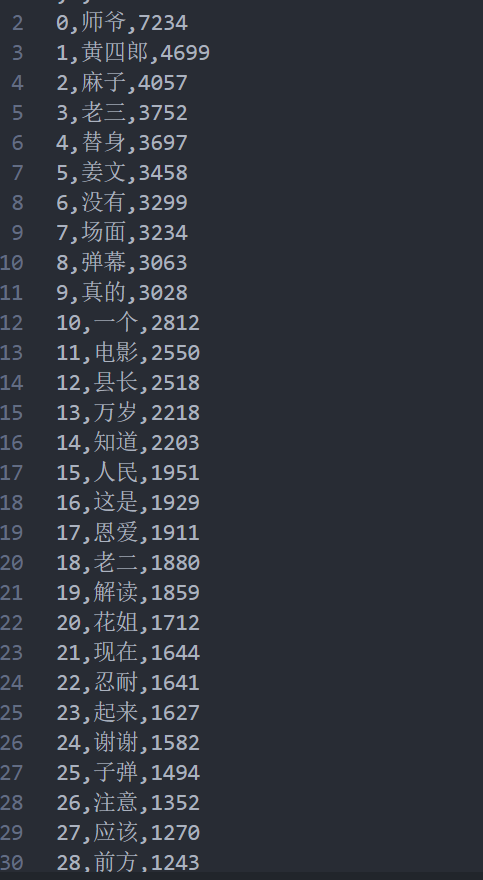
之后,我希望能够获取一个词频统计,根据词频统计来进行制作词云,在词频统计的时候,我又将一些可能出现的单个“词”进行来删去,比如“个”,“谁”等等,具体实现是根据上面筛过一轮之后产生的word_list再进行一轮筛选,将符合要求的词放入列表中,之后根据出现数量的大小进行sort(),并且把统计之后的结果打印并存储在word_csv.csv文件当中
具体实现:
#之后来实现对于词频的统计
word_dict = {}
word_lists = []
for word in word_list:
if len(word) == 1:
continue
else:
word_lists.append(word)
word_dict[word] = word_dict.get(word, 0) + 1
wd = list(word_dict.items()) #使字典列表化
wd.sort(key=lambda x: x[1], reverse=True) #排序
for i in range(50): #生成前二十个高频的词
print(wd[i])
word_csv = wd #将结果写入到csv文件当中
pd.DataFrame(data=word_csv[0:50]).to_csv('word_csv.csv', encoding='UTF-8')
print("已经完成词频统计,可在文件夹1.png中查看词云")运行结果:
词云制作
在这里我们将根据上面已经筛选出的较为高频的50个词来进行制作词云,并且把结果存储在同文件夹下面的1.png当中
具体实现:
string = " ".join(word_lists) #拼接为字符串
w = wordcloud.WordCloud(background_color = "white", font_path = "C:\Windows\Fonts\STXINWEI.TTF",
width=1000,height=700,random_state=42)
w.generate(string)
w.to_file("1.png")运行结果:

统计图绘制
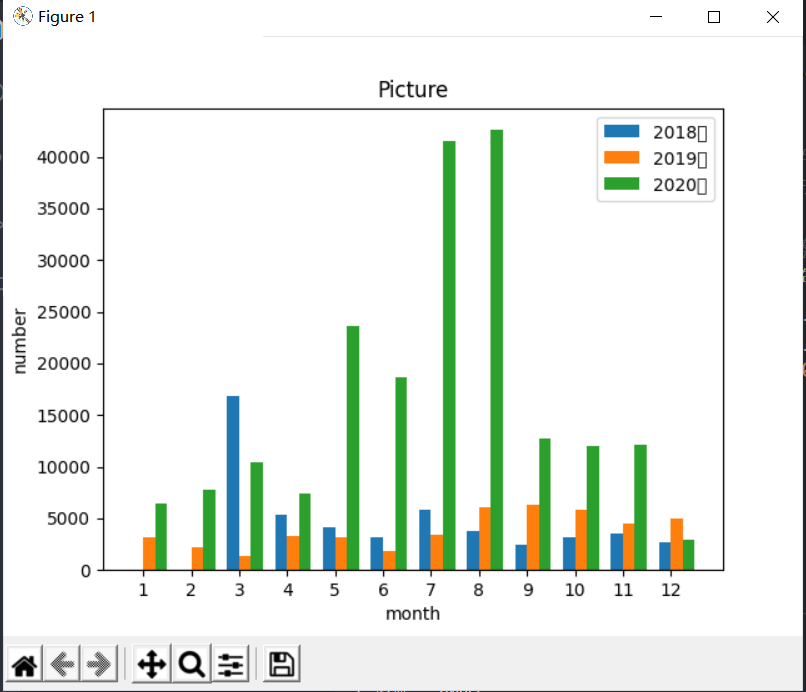
在这里,为了能够得到一些对比出的分析,我将2018-2020不同月份的弹幕量分别统计下来,并用python进行绘制,在这里图片并没有保存,而是仅plt.show()展示
具体实现:
# 之后我希望通过柱状图来能够对于整体的信息有所了解
print("开始绘制统计图,2018-2020年不同月份的弹幕数量的对比,注意此电影在2018.3之前不可看")
y1 = [0,0,16821,5323,4099,3187,5833,3765,2439,3119,3474,2695]
y2 = [3212,2190,1406,3312,3217,1849,3359,6051,6271,5890,4500,5029]
y3 = [6415,7726,10430,7412,23609,18705,41462,42582,12691,12041,12092,2892]
x = np.arange(len(y3))
tick_label = ['1','2','3','4','5','6',
'7','8','9','10','11','12']
bar_width = 0.25
plt.bar(x, y1, width=bar_width, label='2018年')
plt.bar(x + bar_width, y2, width=bar_width, label='2019年')
plt.bar(x + 2 * bar_width, y3, width=bar_width, label='2020年')
plt.xlabel("month")
plt.ylabel("number")
plt.title('Picture')
plt.xticks(x+bar_width/2, tick_label)
plt.legend()
plt.show()运行结果:
分析总结
分词以及词频部分:
- 在这一个部分中,我认为比较重要的是字典的丰富性和针对性,在这一环节的工作中,我认为比较好的一点是我不仅针对于源数据进行了类似“专有名词”的添加以及通用和自己添加的停用词、还在制作词频的时候进一步进行来筛选,从而分析出的词云能够较好地反映出弹幕的热词
词云制作部分:
- 在这一个part,我们可以根据词云看到,一些电影里的“专有名词”是比较多的出现于弹幕当中的,例如:师爷、黄四郎等
统计图绘制
- 在这里,我们可以通过数据对比来分析出一些东西,例如在刚出现的2018年3月,此时弹幕数量是2018年最多的,此后数据发生起伏,而分析可得,很有可能与学生的寒暑假等相关,而之后比较显著的是在2020年的7月和8月,达到了到现在为止的最高弹幕数量(仅针对于这部电影而言),这一方面是因为寒暑假假期,另一方面我认为与疫情的关系也有很大关系
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!