2.Background & Traditional approaches
2.3 Graph Laplacians and Spectral Methods(图拉普拉斯和谱图方法)
邻接矩阵可以无信息损失的表示图,而具有同样的一些效果的矩阵被称为拉普拉斯矩阵,这些矩阵是由邻接矩阵通过变换得到的
2.3.1 Graph Laplacians
- Unnormalized Laplacian非规范化的拉普拉斯式

2.3.2 Graph Cuts and clustering
在这一节当中会介绍使用拉普拉斯矩阵,在完全连通图中给出节点的最优聚类(optimal cluster)。
Graph cuts
首先,我们先需要找的用来衡量分割好坏的量,称之为cut value,而其值的定义如下:
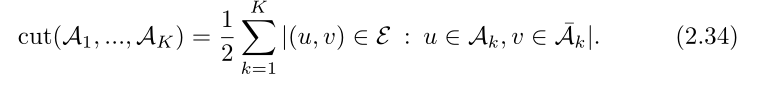
换句话说,就是有的多少条边越过了我们所划分的不同子集的边界,而所谓的最优聚类就算是找到cut value最小的划分方式
缺点:倾向于把图划分成独立的点(稍微有一些不理解!!!)
改进方法:不仅仅是寻找最小化切割的方式,并且要使得分区是较大的,引入ratio cut:
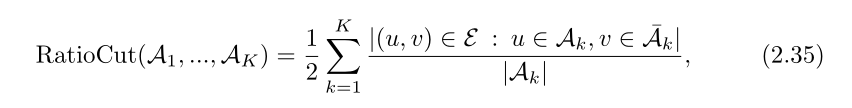
此时,如果是较小的分区,那么分母就会是比较小的,进而ratio cut变大
同时还有一种解决方法——Ncut:
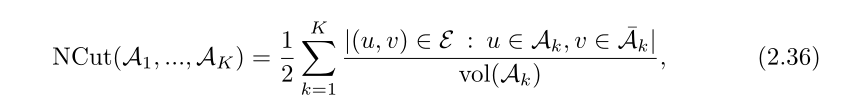
使用拉普拉斯谱最小化RatioCut
目标是通过拉普拉斯谱来找到最小的ratiocut
最小化目标定义为,
为了解决NP难问题,将a的条件放宽到,满足上述2个条件的实值向量即可。
根据瑞利-里兹定理,这个优化问题的解是由L的第二小的特征值对应的特征向量,因此,我们可以通过设置a为第二小的特征向量,来逼近RatioCut的最小值。
总而言之,拉普拉斯矩阵的第二小的特征向量是离散向量的连续近似,它给出了一个最优的聚类分配。
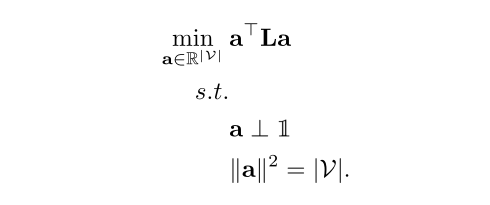
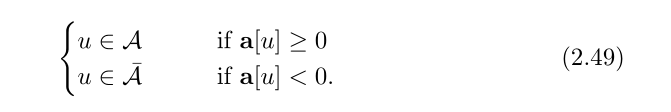
2.3.3 Generalized spectral clustering
上一节,我们找到了一个将图分成两个簇的最优划分。那么,我们也可以将这种方法推广到K个簇的最优划分问题上。
这种一般方法的步骤如下:
4、使用K均值聚类方法来聚合,从而在最优划分的条件下,将图划分成K簇。
2.4 Towards Learned Representations
Part Ⅰ:Node Embedding
3.Neighborhood Reconstruction Methods
什么是node embedding and why we need?
有监督的机器学习都要经历以下几个步骤:首先在原始数据上进行特征工程(因为计算机无法直接识别一个抽象的东西,例如graph或者图片等,需要用计算机能够理解的方式表示出来),得到结构化的数据,接着确定机器学习算法,最终训练得到模型。在这个过程中,特征工程是十分耗时费力的。因此我们更喜欢能够自动获取这些特征的方式(如深度学习)。
而node embedding就是将计算机难以理解的raw data转变为可以理解的structure data,我们通过d维空间上的向量来表示一个节点,d是用来衡量节点信息的,d越大,往往代表节点所包含的信息越大,同时还要求embedding的过程是可逆的,即我们还能从所有向量中推测出原来的图的形式,同时为了评判这个过程的好坏,引入了衡量/相似函数similarity以及损失函数loss
下面是一个案例,将左边的图结构的节点用一个二维向量来表示(当然在实际项目中,embedding向量通常会有几十甚至几百个维度,这里采用二维向量只是为了方便可视化)。可以看到,在右边的图上,比较接近的点在网络中的关系也比较紧密。
但是,传统的深度学习框架很难解决Network Embedding,主要原因有以下几点:
CNN用于固定大小的图像/网格,即像素点的拓扑结构使单一的、固定的。
RNNs或word2vec用于文本/序列,即节点的次序是固定的。
而网络(Networks)的结构要复杂的多得多!网络拥有更加复杂的拓扑结构,且节点的顺序并不是固定的。更有甚者,网络是动态变化的。
因此,我们接下来讨论网络中的embedding nodes。
在第三章中,我们关心的是图的结构信息,所以忽略掉了所有的节点特征以及其他信息,同时我们的目标是在经过embedding之后,d维空间上两个向量的相似性和在图上两个节点的相似性基本上是很像的,在这里,我们首先要定义好什么是图上节点的相似性,之后才能构造编码函数并衡量向量空间上是否相似
第28页
假设左边就是一个我们需要输入的图结构,希望通过一个两层的神经网络来学习我们target node的一个新的表示,首先找到A的邻居B,C,D,之后再找的话就是找BCD的邻居,找到之后将相应的信息进行聚合,聚合之后会得到一层神经网络的结果,之后再次进行聚合,会得到A的经过两层神经网络的消息传递之后的结果
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!